
By John Gruber

Stop searching the App Store. Start telling your phone what to build.
Tynt, the Copy/Paste Jerks
Friday, 28 May 2010
Over the last few months I’ve noticed an annoying trend on various web sites, generally major newspaper and magazine sites, but also certain weblogs. What happens is that when you select text from these web pages, the site uses JavaScript to report what you’ve copied to an analytics server and append an attribution URL to the text. So, for example, if I were using this “service” here on Daring Fireball, and you selected the first sentence of this article, copied it, then switched to another app to paste the text you just copied, instead of pasting just the sentence you selected and intended to copy, you’d instead get:
Over the last few months I’ve noticed an annoying trend on various web sites, generally major newspaper and magazine sites, but also certain weblogs.
Read more: http://daringfireball.net/2010/05/tynt_copy_paste_jerks/#ixzz0oyLiD4Qh
I.e., three blank lines followed by “Read more:”, then the URL from which the text was copied, then an identifying hash code used for tracking purposes.
Among the sites where I’ve seen this in use are TechCrunch (example) and The New Yorker (example). The JavaScript tomfoolery happens with most text copied from the site — whether you’re copying the entire article, a paragraph, or a sentence.
For fragments of a sentence, the behavior changes between different sites. On the New Yorker web site, copying up to seven words from an article works normally — no attribution URL is appended. Copy eight or more words, however, and you get the attribution appendage. On TechCrunch, the attribution appendage again only kicks in for selections of eight or more words. However, on TechCrunch, if the selection consists of only one to three words, when you invoke the Copy command (either by keyboard shortcut or the menu item), you get a popover with search results for the selected text that appears over the contents of the article itself. Madness.
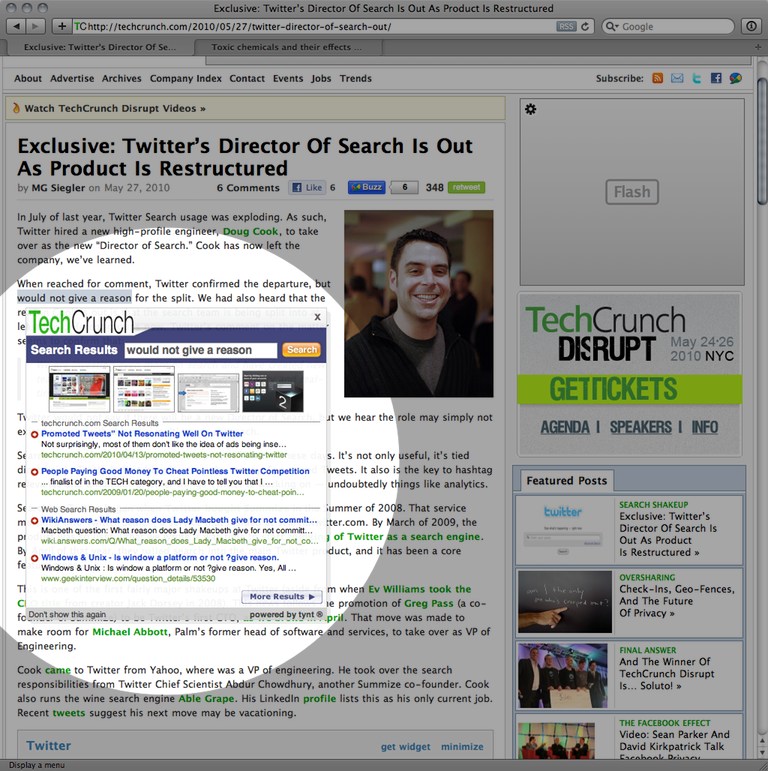{kind=link}
All of this nonsense — the attribution appended to copied text, the inline search results popovers — is from a company named Tynt, which bills itself as “The copy/paste company”.
It’s a bunch of user-hostile SEO bullshit.
Everyone knows how copy and paste works. You select text. You copy. When you paste, what you get is exactly what you selected. The core product of the “copy/paste company” is a service that breaks copy and paste.
The pitch from Tynt to publishers is that their clipboard jiggery-pokery allows publishers to track where text copied from their website is being used, on the assumption that whoever is pasting the text is leaving the Tynt-inserted attribution URL, with its gibberish-looking tracking ID. This is, I believe, a dubious assumption. Who, when they paste such text and find this “Read more:” attribution line appended, doesn’t just delete it (and wonder how it got there)?
It certainly isn’t being appended to help the person copying and pasting the text. The person copying the text knows where it comes from.
If you look at Tynt’s list of client sites, most of them are newspapers and print publishers. It’s no surprise that some of these publications would agree to such a terrible idea — they have no respect for their websites or for their readers. It is surprising, to me at least, that a magazine of the caliber of The New Yorker would agree to it, and it’s even more surprising that a weblog like TechCrunch would go for it.
Now, the nature of my work writing Daring Fireball involves copying and pasting many snippets of text from web sites every day. So this Tynt stuff probably annoys me more (or at least more frequently) than most people. But TechCrunch is itself a weblog that quotes passages from other websites frequently. They’ve instituted a feature that they themselves surely find annoying.
I presume Tynt has plans to eventually insert ads into copied text, but as far as I’ve seen, they aren’t doing so yet. I have no idea what TechCrunch or The New Yorker think they’re getting out of this service. They’re burning some measure of goodwill from their readers in exchange for URL tracking analytics from Tynt identifiers that most people, I bet, delete as soon as they see them after pasting. And even if it does work well — if, in fact, a significant number of people leave the tracking URLs from Tynt in place after they paste — the idea of websites tracking what users copy from their pages is creepy.
Whatever their justification for using Tynt is, I’ll bet it involves repeated use of the phrase “biz dev”. All they’re really doing is annoying their readers. Their websites are theirs, but our clipboards are ours. Tynt is intrusive, obnoxious, and disrespectful. I can’t believe some websites need to be told this.
How to Block Tynt on a PC or Mac
If you use Chrome, you can install this Tynt-blocking extension, which does just what it says on the tin. However, you wind up getting a dialog box each time you encounter a different site using Tynt. (Although only once for each site.)
[Update, 13 July 2010: Drew Thaler’s JavaScript Blacklist extension for Safari 5 works perfectly: just install it and Tynt’s junk just stops working. The /etc/hosts file editing described below is no longer necessary if you install JavaScript Blacklist.]
What I’ve chosen to do is edit my /etc/hosts file to block access system-wide to the tcr.tynt.com server. This is the server from which the Tynt JavaScript code is served to all its “partners”.
Making changes to the hosts file requires administrator privileges, for obvious reasons. If you’re not completely comfortable making changes to an essential Unix configuration file, don’t. This Lifehacker article by Gina Trapani has a good overview of where to find and how to edit your hosts file on Mac OS X or Windows. (BBEdit and its free sibling TextWrangler are my preferred tools for text editing, and both allow you to save files with admin privileges.)
Here’s the line I added to the end of my hosts file:
127.0.0.1 tcr.tynt.com
After saving the hosts file, Tynt’s clipboard-altering nonsense is disabled on all Tynt-using websites I’ve encountered, no matter which browser I use.